Variance Reduction Methods: a Quick Introduction to Quasi Monte Carlo
Reading time: 25 mins.To help finish the basic section as quickly as possible, the first version of this chapter presents the subject matter in a superficial way. It will be improved, developed, and completed once the basic section is itself complete. Quasi-Monte Carlo is a complex topic anyway and requires solid mathematical foundations which can't be explained in a single chapter. A lesson will be devoted later on this topic in the advanced section.
You may have heard the term Quasi-Monte Carlo or Quasi Monte Carlo Ray Tracing and wonder what it means (another one of these magic words people from the graphics community use all the time and each time you hear it you grind your teeth in frustration and think "damn if someone could just explain it to me in simple terms" - that's why we are here for). The math behind Quasi-Monte Carlo can be quite complex, and it requires more than a chapter to study them seriously (entire Mathematics textbooks are devoted to the matter). However, to give you a complete overview of Monte Carlo, we will try in this chapter to give you a quick introduction to this concept, and explain as usual, what it is, and how and why it works.
We will revise this chapter, once all other lessons are completed. QMC (Quasi-Monte Carlo) is a very interesting method and a lesson will be devoted to this topic in the advanced lesson at some point in time. Once we have completed the lesson on Light Transport Algorithms and Sampling, it will become easier to experiment with QMC and show with a more concrete example why it is superior to basic MC.
Introduction
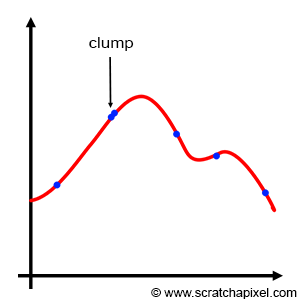
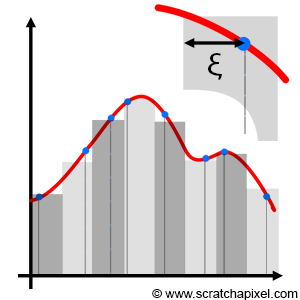
Basic Monte Carlo works. We showed this in the previous chapters. It's a great technique, simple to implement and it can be used to solve many problems, especially in computer graphics. We also studied importance sampling in the previous chapter. It potentially reduces variance by increasing the probability of generating samples where the function being integrated is the most important. However, both basic Monte Carlo and important sampling suffer from a problem known as sample clumping. When the samples are generated, some of them might be very close to each other. They form clumps. Our credit sample being limited we need to use it wisely to gather as much information as possible on the integrand. If two (or more) samples are close to each other, they each provide us with the same information on the function (more or less), and thus while one of them is useful the others are wasted. Importance sampling doesn't save us from clumping. The PDF only controls the density of samples within any part of the integrand, not their numbers. An example of clumping is shown in Figure 1.
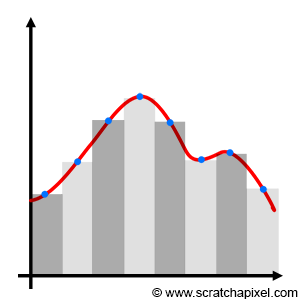
When Monte Carlo is used, we know that samples are randomly chosen. On the other hand (and in contrast to using a Monte Carlo integration), you can use a deterministic quadratic technique such as the Riemann sum, in which the function is sampled at perfectly regular intervals (as shown in Figure 2). So, on one hand, we have perfectly regularly spaced samples (with the Riemann sum) and on the other, you have samples whose positions are completely random (with Monte Carlo integration) which potentially leads to clumping. So, as you may have guessed, you might be tempted to ask: "can we come up with something in between? Can we use some sort of slider to go from completely regularly spaced to completely random, and find some sort of sweet spot somewhere in the middle?" And the quick answer is yes: that's more or less what Quasi-Monte Carlo is all about. Remember that the only reason why we don't use deterministic techniques such as the Riemann sum is that they don't scale up well: they become expensive as the dimension of the integral increases. This is also why MC integration is attractive in comparison.
Nothing imposes us in a Monte Carlo integration to use stochastic samples. We could very well replace \(\xi\) with a series of evenly distributed samples in the MC integration, and the resulting estimate would still be valid. In other words, we can replace random samples with non random samples and the approximation still works. Note that when the points are perfectly evenly distributed then, the Monte Carlo integration and the Riemann sum are similar. If \({s_1, s_2, ..., s_n}\) is a sequence of evenly distributed numbers on the interval [a,b], then:
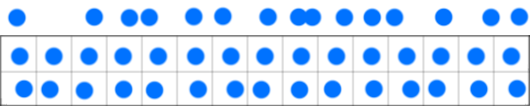
$$\lim_{N \to \infty} {(b-a) \over N} \sum_{i=1}^N f(s_i) = \int_a^b f(x) \: dx,$$where f is a Riemann-integrable function. Though in QMC the sequences commonly used are said to be equidistributed, a term we will explain later. But as an intuitive definition, we can say that equidistributed points are points that are more or less evenly distributed, where the measure of the difference between the actual point distribution compared to a sequence of points perfectly well distributed is called in QMC jargon,�discrepancy. In the world of QMC, we won't speak of variance but more of discrepancy. Again, these will be explained briefly in this chapter and more details in the lesson on QMC in the advanced section. But in short, QMC blurs the lines between random and deterministic sequences. And in effect, the idea behind using these sequences of points is to get as close as possible to the ideal situation in which points are well-distributed, and yet not uniformly distributed. Figure 3 below illustrates this idea. The random sequence at the top shows some clumping and gaps (regions with no samples) and thus is not ideal. The sequence in the middle is purely regular and thus will cause aliasing. The sequence at the bottom is somewhere in between: while it exhibits some property of regularity, the points are not completely uniformly distributed. The idea of dividing the sample space into regular intervals and randomly placing a sample within each one of these sub-intervals is called jittering or stratified sampling.
Quasi-Monte Carlo methods were first proposed in the 1950s about a decade after Monte Carlo methods (which makes sense because once people started to get familiar with Monte Carlo methods, they started to look into ways of improving them). QMC is used in many areas, including engineering, finance, and of course computer graphics (to just name a few), and even though few people can claim to be specialists in the subject, it certainly gained popularity over the last few years. Whether using QMC is better than traditional MC in rendering is often debated. It does converge faster than MC but it has its disatvantages. For example, it can sometimes produce aliasing
Remember that in terms of visual artifact, deterministic techniques such as the Rieman sum produce aliasing while Monte Carlo integration produces noise. Visually noise is often considered as the lesser of two evils, compared to aliasing.
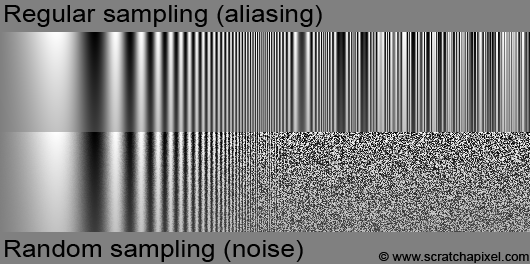
This visual artifact can easily be generated. Figure 4 shows the result of sampling a sine function with increasing frequency. When the sampling rate gets lower than the Nyquist frequency, noise or aliasing shows up. A lesson of the advanced section is devoted to aliasing in which the concept of Nyquist limit is explained and we will explain aliasing from a mathematical point of view when we get to the topic of sampling and Fourier analysis (which we kept for the end).
#include <cstdlib>
#include <cstdio>
#include <cmath>
#include <fstream>
#include <stdint.h>
float evalFunc(const float &x, const float &y, const float &xmax, const float &ymax)
{
return 1. / 2. + 1. / 2. * powf(1. - y / ymax, 3.) * sin( 2. * M_PI * ( x / xmax) * exp(8. * (x / xmax)));
}
int main(int argc, char **argv)
{
uint32_t width = 512, height = 512;
uint32_t nsamples = 1;
unsigned char *pixels = new unsigned char[width * height];
for (uint32_t y = 0; y < height; ++y) {
for (uint32_t x = 0; x < width; ++x) {
float sum = 0;
for (uint32_t ny = 0; ny < nsamples; ++ny) {
for (uint32_t nx = 0; nx < nsamples; ++nx) {
#ifdef REGULAR
sum += evalFunc(x + (nx + 0.5) / nsamples, y + (ny + 0.5) / nsamples, width, height);
#endif
#ifdef RANDOM
sum += evalFunc(x + drand48(), y + drand48(), width, height);
#endif
}
}
pixels[y * width + x] = (unsigned char)(255 * sum / (nsamples * nsamples));
}
}
std::ofstream ofs;
ofs.open("./sampling.ppm");
ofs << "P5\n" << width << " " << height << "\n255\n";
ofs.write((char*)pixels, width * height);
ofs.close();
delete [] pixels;
return 1;
}
Stratified Sampling
Before we look into generating sequences of quasi-random numbers, we will first talk about a method that is somewhere in between random and regular distributed samples. This method is called stratified sampling and was introduced to the graphics community by Robert L. Cook in a seminal paper entitled Stochastic Sampling in Computer Graphics (which he published in 1986 but the technique was developed at Pixar in 1983). This paper is quite fundamental to the field of computer graphics and will be studied in depth in the lesson on Sampling (in the basic section). In this paper, Cook studied the quality of different sampling strategies notably by using Fourier analysis which is with Monte Carlo theory, another one of these really large topics which we better keep for the end. In his paper, Cook didn't call the method stratified sampling but jittered sampling, but nowadays it only seems to be known under the former name.
The concept of stratified sampling is very simple. It combines somehow the idea of regular and random sampling. The interval of integration is divided into N subintervals or cells (also often called strata), samples are placed in the middle of these subintervals but are jittered by some negative or positive random offset which can't be greater than half the width of a cell. In other words, if h is the width of the cell: \(-h/2 \leq \xi \leq h/2\). Technically though we generally place the sample on the left boundary of the cell and jitter its position by \(h * \xi\). In other words, we simply place a random sample within each stratum. The result can be seen as a sum of N Monte Carlo integrals over sub-domains.
$$\langle F^N \rangle = { (b-a) \over N} \sum_{i=0}^{N-1} f(a + ( { {i+\xi} \over N } ) (b-a)).$$Extending this idea to 2D is straightforward. The domain of integration (often a unit square, such as pixel for instance) is divided into N * M strata, and a random sample is placed within each cell. Again, this can easily be extended to higher dimensions. In the case of stratified sampling, variance reduces linearly with the number of samples (\(\sigma \propto 1 / N\)). In almost all cases, stratified sampling is superior to random sampling and should be preferentially used.
Stratified sampling superiority over random sampling shall be proven in a future revision of this lesson (and also that variance reduces linearly with the number of samples). Other stratification approaches exist such as N-Rooks or Latin hypercube sampling, multi-jittered and orthogonal array sampling, and multi-stage N-Rooks sampling.
Quasi Random Numbers and Low-Discrepancy Sequences
Quasi-Monte Carlo integration relies on sequences of points with particular properties. As explained in the introduction, the goal is to generate sequences of samples that are not exactly uniformly distributed (uniformly distributed samples cause aliasing) and yet appear to have some regularity in the way they are spaced. Mathematicians introduced the concept of discrepancy to measure the distribution of these points. Intuitively, the discrepancy can be seen (interpreted) as a measure of how the samples deviate in a way from a regular distribution. Random sequences have a high discrepancy while a sequence of uniformly distributed samples would have a zero discrepancy. The sort of sequences we are after is the ones with the lowest possible discrepancy but not a zero discrepancy. Some sequences minimize randomness (the deviation of the position of the actual sample from a uniform distribution should be as small as possible) but are not exactly uniform (i.e. we are not interested in sequences with 0 discrepancies).
We will come back to the concept of discrepancy and give its mathematical definition in a future revision of this lesson. In the meantime, you may want to have a look at this Wikipedia article on low-discrepancy sequences.
Example: the Van der Corput Sequence
Algorithms for generating low discrepancy sequences were found in the 1950s (it will hopefully be clear to you how computer technology has influenced their design). Interestingly, these algorithms are often quite simple to implement (they often only take a few lines of code) but the mathematics behind them can be quite complex. These sequences can be generated in different ways but for this introduction, we will only consider a particular type of sequence called Van der Corput sequence (many over-algorithms are constructed using this approach). Having one example to play with, should at least show you what these sequences look like (and help us to study some of their basic properties). To generate a Van der Corput sequence, you need to be familiar with the concept of radical and radical inverse which we will now explain (we will also explain why it's called radical inverse further down).�
Every integer number can be decomposed or redefined if you prefer in a base of your choice. For example, our numerical system uses a base ten. Also, recall that any number (integer) to the power of zero is one (\(10^0=1\)). So in base 10 for instance, the number 271 could be defined as \(\color{red}{2}\times\color{green}{10^2} + \color{red}{7} \times \color{green}{10^1} + \color{red}{1} \times \color{green}{10^0}\). Mathematically we could write this sum as:
$$n = \sum_{i=1}^N \color{red}{d_i} \color{green}{b^{i-1}}.$$where \(b\) is the base in which you want to define your number (in our example \(b=10\)) and the \(d\)'s which are called digits, are in our example the numbers 2, 7 and 1\. The same method can be used with a base two which as you know, is used by computers to encode numbers. The first bit (the one to the right of a byte) represents 1 (\(2^0\)).
00000001
The second bit is 2 (\(2^1\)).
00000010
The third bit is 4 (\(2^2\)).
00000100
The fourth bit is 8 (\(2^3\)), and so on.
00001000
If you combine these bits you can create more numbers. For example, number 3 can be encoded by turning on the first and second bits. Adding up the numbers they represent gives 3 (\(2^0 + 2^1 = 1 + 2 = 3\)).
00000011
This byte encodes the number 11:
00001011$$(1 \times 2^0 + 1 \times 2^1 + 0 \times 2^2 + 1 \times 2^3 = 1 + 2 + 0 + 8 = 11).$$
Which we can write mathematically as:
$$n = \sum_{i=1}^{8} d_i 2^{i-1}.$$where \(d_i\) in base 2 can either be 0 or 1\. With this in hand, we can now decompose any integer into a series of digits in any given base (we call this, a digit expansion in base b). Now note that the number we can recreate with this sequence is a positive integer. In other words, you can see this number as being a series of 0 and 1 on the left inside of an "imaginary"�decimal point.
1.
11.
111.
1111.
11111.
111111.
1111111.
11111111.
The idea behind the Van der Corput sequence is to mirror these bits around this imaginary decimal point. For example, our number 11, becomes:
00001011. (number 11 in base 2)
.11010000 (digits of number 11 in base 2 mirrored about a decimal point)
That can be done by making a slight change to the equation which we used for computing n:
$$ \begin{equation} \tag{equation 1} \phi_b(n) = \sum_{i=1}^N { d_{i-1} \over b^i }. \end{equation} $$which is equivalent to:
$$\phi_b(n) = {d_0 \over {2^1}} + {d_1 \over {2^2}} ... + {d_{N-1}\over {2^N}}.$$As you can see, instead of multiplying the digit \(d_i\) by \(b^{i-1}\), we divide it instead by \(b^{i}\) (we take its inverse). We call this function the radical inverse function \(\phi_b(n)\) in base b and it computes a one-dimensional Van der Corput sequence (why it's called "radical inverse" is explained further down in a note). The coefficients \(d_i\) are given as explained, by the digit expansion in base b of n:
Keep in mind that:
$${1 \over b^n} = 1 \times b^{-n}.$$If n = 1 for example, \(\phi_2(1) = 1 \times 2-{1} = 1 \times 0.5 = 0.5\) (in base 2). If n = 3, \(\phi_2(3) = 1 \times 2^{-1} + 1 \times 2^{-2} = 0.75\). The following table shows the first few numbers of the Van der Corput sequence (in base 2).
\(i\) decimal |
\(i\) binary |
\(\phi_2(i)\) binary |
\(\phi_2(i)\) decimal |
|---|---|---|---|
0 |
0000.0 |
0.0000 |
0.0 |
1 |
0001.0 |
0.1000 |
0.5 |
2 |
0010.0 |
0.0100 |
0.25 |
3 |
0011.0 |
0.1100 |
0.75 |
4 |
0100.0 |
0.0010 |
0.125 |
5 |
0101.0 |
0.1010 |
0.625 |
... |
|||
11 |
1011.0 |
0.1101 |
0.8125 |
... |
Implementing this algorithm is quite simple. The first task is to find a way of computing the digit expansion. The function we need is the modulus operator: num % 2 computes the remainder when num (an integer) is divided by 2. So for example 1 % 2 = 0, 2 % 2 = 0, 3 % 2 = 1, 4 % 2 = 0, and so on. So in essence num % 2 tells us whether the current value of n is a multiple of the base or not. In a binary integer, the only bit that is making the number odd or even is the right-most bit (the least significant bit which has the bit position 0). So if the number is even (n % 2 = 0), this last bit should be 0.
int n = 11; int base = 2; int d0 = n % base; //it returns either 0 or 1
The next step is to start adding up the result of the digit divided by the base raised to the power of the digit position plus one (as in equation 1).
int n = 11; float result = 0; int base = 2; int d0 = n % base; //it returns either 0 or 1 int denominator = base; //2 = powf(base, 1) result += d0 / denominator;
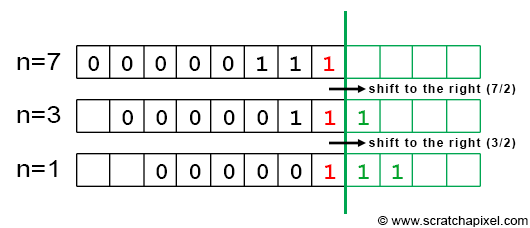
The next step is to compute the next digit in the expansion. To do so, we will simply divide n by the base. For example, if n = 11, then n / 2 = 5. Keep in mind we work with integers. Why are we doing this? Let's take an example. When the last three bits of a binary integer are set to 1 (and all the others to 0), we get the integer 7. Our test 7 % 2 gives 1, which set our first bit to 1. Now that we know the value for the right-most bit, we can as well remove it from the number by shifting it to the right. This gives us a new digit number and since we know that each bit in a digit number is twice the number represented by the bit on its left, shifting the least significant bit to the right (which is another way to say that we remove it) corresponds to dividing the number by 2. For example, if we remove the right-most bit in 111 (the integer 7) we get 11 which is the integer 3 which is also, as you can see, 7 divided by 2. This idea is illustrated in Figure 6.
As you can see in Figure 6, by successively dividing n by 2, we will be able to test if the next digit in the expansion should be set to 1 or 0 by just looking at the result of n % 2. Let's take another example with n = 11:
n= |
n%2= |
n/2 |
n binary |
(\d_i\) |
|---|---|---|---|---|
11 |
1 |
5 |
00001011 |
\(d_0=1\) |
5 |
1 |
2 |
x0000101 |
\(d_1=1\) |
2 |
0 |
1 |
xx000010 |
\(d_2=0\) |
1 |
1 |
0 |
xxx00001 |
\(d_3=1\) |
0 |
- |
- |
- |
- |
Finally here is the complete implementation of the algorithm:
#include <iostream>
#include <cmath>
float vanDerCorput(int n, const int &base = 2)
{
float rand = 0, denom = 1, invBase = 1.f / base;
while (n) {
denom *= base; //2, 4, 8, 16, etc, 2^1, 2^2, 2^3, 2^4 etc.
rand += (n % base) / denom;
n *= invBase; //divide by 2
}
return rand;
}
int main()
{
for (int i = 0; i < 10; ++i) {
float r = vanDerCorput(i, 2);
printf("i %d, r = %f\n", i, r);
}
return 0;
}
Question from a reader: "why is it called Radical Inverse"? In mathematics, a radical function is a function that has a variable inside a \(\sqrt{}\). However, radical in the context of the Van der Corput algorithm has nothing to do with the square root sign. Rather, it's the adjective from radix, which is another word for the base, as in base-10, base-2, and so on. You're taking the expansion to base b - the expansion with radix b - and writing it backward - "inverting" it.
The Van der Corput sequence has been extended to multi-dimensions by Halton (1960), Sobol (1967), Faure (1982), and Niederreiter (1987). For more information, check the lesson on Sampling in the advanced section. The Halton sequence uses different Van der Corput sequences in different bases, where a base is a prime number (2, 3, 5, 7, 11, etc.). For example, if you want to generate 2D points, you can assign a Van der Corput sequence in base 2 to the x coordinates of the points, and another sequence in base 3 to the point's y coordinate.
$$ \begin{array}{l} P[n].x = vanDerCorput(n, 2)\\ P[n].y = vanDerCorput(n, 3)\\ ... \end{array} $$The Hammersley sequence uses a Van der Corput sequence in base 2 for one of the coordinates and just assigns \(n / N\) to the other (assuming your point is a 2D point).
$$ \begin{array}{l} P[n].x = vanDerCorput(n, 2),\\ P[n].y = \dfrac{n}{N}. \end{array} $$The following code creates a Halton sequence for generating 2D points:
#include <iostream>
#include <cmath>
float vanDerCorput(int n, const int &base = 2)
{
...
}
int main()
{
Point2D pt;
for (int i = 0; i < 10; ++i) {
pt.x = vanDerCorput(i, 2); //prime number 2
pt.x = vanDerCorput(i, 3); //prime number 3
printf("i %d, pt.x = %f pt.y\n", i, pt.x, pt.y);
}
return 0;
}
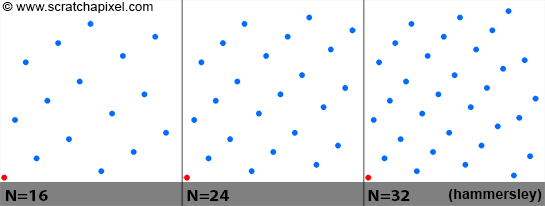
The figure above shows a plot of points from a 2D Hammersley sequence for a different number of samples (N = 16, 24, and 32). Note that the point (0,0) in red, is always in the sequence and that points are nicely distributed for all values of N. The code used to generate the Van der Corput sequence can be optimized using bit operations (for instance dividing an integer by 2 can be done with a bit shift operation). Because the sequence is called with incrementing values of n, results of the previous calculation could also be re-used (which could also speed up the generation of the samples). The next revision of this lesson will include an optimized version of this function.
Quasi-Monte Carlo
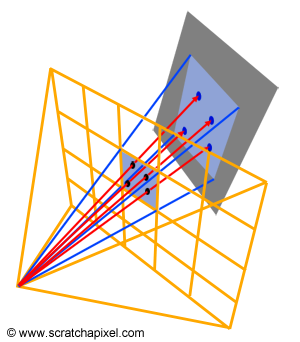
The idea behind quasi Monte Carlo is obviously to use quasi-random sequences in the generation of samples rather than random samples. These sequences are very often used to generate pixel samples. In this lesson and the lesson Introduction to Shading and Radiometry, we showed how Monte Carlo integration could be used to approximate radiance passing through a given pixel (Figure 7). Random sampling is of course the easiest (at least the most basic) way of generating these samples. We can also use stratified sampling (which is better than random sampling) or of course quasi-random sequences (like the Halton or the Hammersley sequence which we talked about in this chapter). When low-discrepancy sequences are used, we speak of Quasi-Monte Carlo ray tracing (as opposed to Monte Carlo ray tracing which is using random or stratified sampling). Note that computing the radiance of a pixel is only one example of Monte Carlo integration in which low-discrepancy sequences can be used. Halton, Hammersley, or any other such sequences are also commonly used in shading (this will be explained in the next lessons).
Pros and Cons of Stratified Sampling & Quasi-Monte Carlo

QMC has a faster rate of convergence than random sampling and this is certainly its main advantage from a rendering point of view (we will explain mathematically why in a future revision of this lesson). Images produced with low-discrepancy sequences, have generally less noise and a better visual quality than images produced with random sampling (for the sample number of samples). With stratified sampling, it is not always possible to efficiently generate samples for arbitrary values of N (try to generate 7 2D samples for instance using stratified sampling) while with low-discrepancy sequences, this is not a problem. Furthermore, note that if you want to change the value of N, you can do so without losing the previously calculated samples. N can be increased while all samples from the earlier computation can still be used. This is particularly useful in adaptive algorithms in which typically a low number of samples is used as a starting point and more samples are generated on the fly in areas of the frame where variance is high.
Cons: as mentioned earlier in this chapter, QMC can suffer from aliasing and moreover, because low-discrepancy has a periodic structure, they can generate a discernible pattern (Figure 8). This is particularly hard to avoid as sequences are potentially re-used from one pixel to another. Getting rid of the structure can require additional work (such as rotating the samples, etc.). This potentially makes a robust implementation of LDS in a renderer more complex than the stratified sampling approach which is simple to implement. QMC has been been quite an active field of research since the 2000s. While low discrepancy sequences are now considered a viable alternative to other sampling methods, there is still an active debate in the graphics community as to whether they are superior to other methods and worth the pain. A. Kensler for instance has recently published a new technique for generating stratified samples which is competitive with low discrepancy quasi-Monte Carlo sequences (see reference below).
Generally, generating (good) random sequences is a complex art, and studying their properties involved complex techniques (such as Fourier analysis). A chapter can only give a very superficial overview of these methods.
A Final World
This concludes our introduction to Monte Carlo methods. These lessons hopefully gave you a good understanding of what Monte Carlo methods are, and how and why they work. While we spoke about Monte Carlo ray tracing a few times in the last few lessons, you may still want to see how all the things we learned so far apply to rendering and ray tracing in particular. This is the topic of our next lesson.
Reference
Stochastic Sampling in Computer Graphics, Robert L. Cook, Siggraph 1986.
Efficient Multidimensional Sampling, T. Kollig, and A. Keller, 2002.
Correlated Multi-Jittered Sampling, A. Kensler, 2013.