Reading and Writing Images (A Simple Image Class)
Reading time: 20 mins.It seems quite natural as a prerequisite to any of the lessons devoted to image processing that we learn about reading and writing images. In this lesson, we will also write a very basic Image class which will be extended over time. Obviously many designs are possible but we will just stick with a very simple one to start with. Our basic image class will only support floating point images (a must these days) composed of three channels only. You can easily extend this class as an exercise, for example you can use template to define the image data type and the number of channels on the fly. Without any further due, let's start to quickly revisit what we know about images and implement some simple code to read and write them as well as store them in memory. In the next lesson, we will extend our basic C++ class to support basic image manipulations.
We are familiar with the concept of digital images. As a quick definition let's just say that an image in the digital world, is stored or represented as a 2D array of pixels. The image resolution defines the dimension of this 2D array. The width (horizontal dimension) and the height (vertical dimension) define the overall resolution of the image. A pixel in the digital world is generally defined by three digital values, one for each elementary or primary color. If you work with an additive color system (which computer screens are using) these colors are red, blue and green (in a subtractive color system these primary colors are cyan, magenta and yellow). In the old times, when computer memory and disk space were limited, pixels values were often stored using the least possible number of bytes. With 1 byte (8 bits) you can encode or represent 256 different values per color. If you use three bytes to encode the red, green and blue color of a pixel respectively, you can define up to 16.8 millions different colors. This format is know as Truecolor. The number of bits (not bytes) used per pixel is often abbreviated with the acronym bpp; it stands for bits per pixel. Truecolor uses 24 bpp. Sometimes the number of bits used is defined per channel (i.e. per color). In this case the acronym is bpc (bits per channel) but it is not often used. The number of bits used for each color component of a single pixel, is known as the color depth or bit depth. If Truecolor is generally enough for the Internet, most image formats used by professionals in the video or film industry encode pixel color as three single (or half) floating point precision numbers (the type float in C++). This means that a single pixel uses 12 bytes of memory (or 96 bpp). A high definition image (typically 1920x1080 pixels) requires roughly 24 Mbytes of storage (assuming no compression). Storing pixel color as floats was originally motivated by the need for high dynamic range images (or HDR images), images capable of storing the wider range of colors and light levels one can observe in the physical world. This concept will be reviewed in a separate lesson. From a programming point of view, all we need to do, is to create a simple Image class, in which we will store the width and the height of the image, as well as a 1D array of pixels (you can use a two dimensional arrays if you want, but this is not necessarily more practical and is not as efficient). We need two constructors, one to create an empty image and one to create an image with a user specified resolution (line 20) which can also be filled with a given constant color (this color default to black). The pixels themselves are represented with a special structure named rib. This is very convenient because we can write operators to manipulate the three floats of a pixel at once. It is trivial to access pixels from the image by overloading the bracket operator [] and applying every mathematical operations we want on these pixels: multiplying them, comparing them, adding them, etc. The method friend float& operator += (...) is interesting. It can be used to compute the brightness of a pixel and accumulate the result into a float. We will use it in the next chapters. Finally pixels are stored in the image as a 1D array of Rgb elements. The size of this area is equal to the width of the image multiplied by the image height. It is not necessary to multiply this number by the number of channels since each pixel (of type Rgb) already holds the memory to store three colors.
#include <cstdlib>
#include <cstdio>
class Image
{
public:
// Rgb structure, i.e. a pixel
struct Rgb
{
Rgb() : r(0), g(0), b(0) {}
Rgb(float c) : r(c), g(c), b(c) {}
Rgb(float _r, float _g, float _b) : r(_r), g(_g), b(_b) {}
bool operator != (const Rgb &c) const
{ return c.r != r || c.g != g || c.b != b; }
Rgb& operator *= (const Rgb &rgb)
{ r *= rgb.r, g *= rgb.g, b *= rgb.b; return *this; }
Rgb& operator += (const Rgb &rgb)
{ r += rgb.r, g += rgb.g, b += rgb.b; return *this; }
friend float& operator += (float &f, const Rgb rgb)
{ f += (rgb.r + rgb.g + rgb.b) / 3.f; return f; }
float r, g, b;
};
Image() : w(0), h(0), pixels(nullptr) { /* empty image */ }
Image(const unsigned int &_w, const unsigned int &_h, const Rgb &c = kBlack) :
w(_w), h(_h), pixels(NULL)
{
pixels = new Rgb[w * h];
for (int i = 0; i < w * h; ++i)
pixels[i] = c;
}
const Rgb& operator [] (const unsigned int &i) const
{ return pixels[i]; }
Rgb& operator [] (const unsigned int &i)
{ return pixels[i]; }
~Image()
{ if (pixels != NULL) delete [] pixels; }
unsigned int w, h; //Image resolution
Rgb *pixels; //1D array of pixels
static const Rgb kBlack, kWhite, kRed, kGreen, kBlue; //Preset colors
};
const Image::Rgb Image::kBlack = Image::Rgb(0);
const Image::Rgb Image::kWhite = Image::Rgb(1);
const Image::Rgb Image::kRed = Image::Rgb(1,0,0);
const Image::Rgb Image::kGreen = Image::Rgb(0,1,0);
const Image::Rgb Image::kBlue = Image::Rgb(0,0,1);
int main(int argc, char **argv)
{
Image *img = new Image(512, 512);
return 0;
}
Read and Write Images: PPM, a Simple Image Format
Photoshop and Preview (on Mac) can read and write PPM files. In Photoshop the format is called Portable Bit Map. If you write them out with Photoshop you will need to change the extension of the file from .bpm to .ppm (or change the file extension to .bpm in your code).

The PPM format is the simplest image file format someone can design. It is not optimised at all, don't use any form of compression thus the image file on disk is large compared to other formats such PNG or JPEG. However, the code to read and save PPM images in and out is incredibly simple to write and for this reason, this format is very useful when you need your program to read or write images. Use it to prototype some ideas and replace it later by a more sophisticated format (one that supports compression and potentially some other useful features such as arbitrary number of channels, etc.). This lesson is not a complete introduction to the PPM format. Even though basic (very close to a raw format) the PPM format has its subtleties. It can for example be used to store color or black and white images, as well as pixels's data in ascii or binary mode. In this lesson we will only work with binary files and color images.
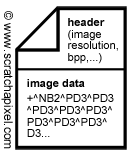
Most image file formats are designed the same way. At the top of the file is usually stored was is called a header. It's generally a structure in which are defined the standard properties of the image: its resolution of course, but also the number of images planes stored in the image, the number of bits per channel, whether the data is compressed or not, which compression algorithm the pixels are processed with, etc. Generally, the only really necessary information is the image resolution. Everything else is optional. It can also contain meta data such as who created the file, the date and the time when the file was generated, etc. If it comes from a digital camera these meta data can also contain information about the lens being used, the camera settings such as shutter speed, the aperture, etc that were used when the picture was taken. This information can be useful as we will see when we get to the lesson on HDR images. Finally, the header is almost always directly followed by the image data itself. The way the data is encoded really varies from a file format to another. Colors of pixels can be stored together (as with the PPM file format) or each plane can be stored separately. Colors can be stored with integers, chars, floats, etc. Image data can also be compressed (generally they are).
The header (the few lines at the top of the file providing the necessary information about the image we are about to read) is defined by three lines. The first line contains a string which can either be "P1", "P2", ... "P6". We are only concerned by "P6" PPM images which stands for binary color images. The next line contains two integers representing the resolution of the image. The third line contains an another integer representing the number of levels each color is encoded with (i.e. the number of grey values between black and white, generally 255). You can insert comments in the header; they start with the letter '#', but we will ignore them in this lesson.
P6 640 480 255 # comment but we won't support them for now
In the PPM format, colors are encoded using 24 bpp. In other worlds each color is encoded as 1 bytes (in C++ an unsigned char). Each pixel is encoded in the file as a sequence of three bytes (Figure 2), one for each color:
R1G1B1R2G2B2R3G3B3...
Pixels are encoded in scanline order, from the first row to the last row in the image, for left to right (Figure 2). In other words the first three bytes in the file are for the pixel at location (1,1) in the image (where (1,1) denotes the upper left corner of the image), and the last three bytes in the file represent the lower right pixel in the frame (location (640, 480) assuming the image has resolution 640x480). Let's have a look at our code to read a PPM file:
Image readPPM(const char *filename)
{
std::ifstream ifs;
ifs.open(filename, std::ios::binary);
// need to spec. binary mode for Windows users
Image src;
try {
if (ifs.fail()) {
throw("Can't open input file");
}
std::string header;
int w, h, b;
ifs >> header;
if (strcmp(header.c_str(), "P6") != 0) throw("Can't read input file");
ifs >> w >> h >> b;
src.w = w;
src.h = h;
src.pixels = new Image::Rgb[w * h]; //this is throw an exception if bad_alloc
ifs.ignore(256, '\n'); //skip empty lines in necessary until we get to the binary data
unsigned char pix[3]; //read each pixel one by one and convert bytes to floats
for (int i = 0; i < w * h; ++i) {
ifs.read(reinterpret_cast<char *>(pix), 3);
src.pixels[i].r = pix[0] / 255.f;
src.pixels[i].g = pix[1] / 255.f;
src.pixels[i].b = pix[2] / 255.f;
}
ifs.close();
}
catch (const char *err) {
fprintf(stderr, "%s\n", err);
ifs.close();
}
return src;
}
Note that some special cases need to be taken care of carefully. For example when the file we want to read doesn't exist on disk, or when its size is 0 (which is unlikely but you still need to consider this option). Some programs also insert an empty line after the header when the write a PPM file out. The code removes these lines if they exist. Note that the code is really not optimized. You could read the entire block of data in memory then convert it to float, or at least read one line of pixel data at a time. The conversion from byte to float only requires a division by 255. We know that a byte can only encode a number between 0 and 255 where 0 represents black and 255 white. By dividing this value by 255, we remap the pixel color to a float in the interval [0,1] where 0 represents black and 1 represents white on the screen.
Important question from a reader: "from a programming point of view, is it efficient to return an image?" Good question. Consider the following code:
Image dst= readPPM("./lena.ppm");
First you must do a copy within the function reading the PPM file in the return statement (src itself is copied to a temporary variable returned by the function). Then when dst is initialised, the data from this temporary variable is copied once more to dst itself. This implies two copies (and a series of allocations) of potentially large memory blocks which indeed would be inefficient. Though in our particular case, src.pixels is a pointer to a dynamically allocated block of memory and copying pointers values isn't in itself too bad (though this will lead to more problems as we will show later). However, nowadays, C++ allows what's known as copy elision (this will only work if you have a recent compiler). The idea is that your compiler will find out that the type of the returned function is the same as the type of the variable you allocate the result of this function to. In this situation, dat will actually be initialised as if it was created in the readPPM function directly and all copies previously involved will be omitted (or elided). In other words, your compiler will sort of replace src with dst in the function readPPM() for you. This is called a return value optimization (or RVO for short). One of the standard solutions to this problem was to return a pointer to a dynamically allocated instance of the class Image. Pointer initialization or assignment is far less costly than a copy:
Image* readPPM(...)
{
Image *img = new Image(...);
...
return img;
}
Image *img = readPPM(...);
But with copy elisions, this is not necessary anymore. In short, with most modern compilers, this code should be efficient and shouldn't require any copy of the image data at all (if copy elision works).
In:
Image operator + (const Image &img) const { Image tmp; // ... return tmp; }
You are creating and returning an object of the same type as the return type of the function. This implies that return tmp; will consider tmp as if it was an rvalue as per 12.8/32:
When the criteria for elision of a copy operation are met or would be met save for the fact that the source object is a function parameter, and the object to be copied is designated by an lvalue, overload resolution to select the constructor for the copy is first performed as if the object were designated by an rvalue.
The mentioned criteria are given in 12.8/31, in particular, the first bullet point says:
— In a return statement in a function with a class return type, when the expression is the name of a non-volatile automatic object (other than a function or catch-clause parameter) with the same cv-unqualified type as the function return type, the copy/move operation can be omitted by constructing the automatic object directly into the function’s return value
Actually, a careful reading of 12.8/31 says that in your case compilers are allowed (and the most popular ones do) to omit the copy or move altogether. This is the so called return value optimization (RVO). Indeed, consider this simplified version of your code:
struct Image {
Image() {
}
Image(const Image&) {
std::cout << "copy\n";
}
Image(Image&&) {
std::cout << "move\n";
}
Image operator +(const Image&) const {
Image tmp;
return tmp;
}
};
int main() {
Image src;
Image copy = src + src;
}
Compiled with GCC 4.8.1, this code produces no output, that is, no copy of move operation is performed. Let's complicate the code a little bit just to see what happened when RVO cannot be performed.
Image operator +(const Image&) const {
Image tmp1, tmp2;
if (std::rand() % 2)
return tmp1;
return tmp2;
}
Without much of details, RVO cannot be applied here not because the standard forbids so but for other technical reasons. With this implementation of operator +() the code outputs move. That is, there's no copy, only a move operation. A last word. It's not advisable to do return std::move(tmp); because it prevents RVO. Indeed, with this implementation:
Image operator +(const Image&) const {
Image tmp;
return std::move(tmp);
}
The output is move, that is, the move constructor is called, whereas, as we've seen, with return tmp no copy/move constructor is called. That's the correct behaviour because the expression being return std::move(tmp) is not the name of a non-volatile automatic object as required by the RVO rule quoted above. The implementation of operator +() which introduces tmp and tmp2 is rather an artificial way to prevent RVO. Let's go back to the initial implementation and consider another way of preventing RVO which also shows the complete picture: compile the code with the option -fno-elide-constructors (also available in clang). The output (in GCC but it might vary in clang) is:
move move
When a function is called stack memory is allocated to build the object to be returned. I emphasise that this is not the variable tmp above. This another unnamed temporary object. Then, return tmp; triggers a copy or move from tmp to the unnamed object and the initialisation Image cry = src + src; finally copy/move the unnamed object into cry. That's the basic semantics. Regarding the first copy/move we have the following. Since tmp is an lvalue the copy constructor would normally be used to copy from tmp to the unnamed object. However, the special clause above makes an exception and says that tmp in return tmp; should be considered as if it was an rvalue. Hence the move constructor is called. In addition, when RVO is performed, the move is elided and tmp is actually created on top of the unnamed object. Regarding the second copy/move it's even simpler. The unnamed object is an rvalue and therefore the move constructor is selected to move from it to cry. Now, there's another optimization (which is similar to RVO but AFAIK doesn't have a name) also stated in 12.8/31 (third bullet point) that allows the compiler to avoid the use of the unnamed temporary and use the memory of cpy instead. Therefore, when RVO and this optimization are in place tmp, the unnamed object and cry are essentially "the same object". There seems to be some confusion as to how the RVO (Return Value Optimization) works. A simple example:
struct A {
int a;
int b;
int c;
int d;
};
A create(int i) {
A a = {i, i+1, i+2, i+3 };
std::cout << &a << "\n";
return a;
}
int main(int argc, char*[]) {
A a = create(argc);
std::cout << &a << "\n";
}
0xbf928684 0xbf928684
Surprising ? Actually, that is the effect of RVO: the object to be returned is constructed directly in place in the caller. How ? Traditionally, the caller (main here) will reserve some space on the stack for the return value: the return slot; the callee (create here) is passed (somehow) the address of the return slot to copy its return value into. The callee then allocates its own space for the local variable in which it builds the result, like for any other local variable, and then copies it into the return slot upon the return statement. RVO is triggered when the compiler deduces from the code that the variable can be constructed directly into the return slot with equivalent semantics (the as-if rule). Note that this is such a common optimization that it is explicitly white-listed by the Standard and the compiler does not have to worry about possible side-effects of the copy (or move) constructor. When ? The compiler is most likely to use simple rules, such as:
// 1. works
A unnamed() { return {1, 2, 3, 4}; }
// 2. works
A unique_named() {
A a = {1, 2, 3, 4};
return a;
}
// 3. works
A mixed_unnamed_named(bool b) {
if (b) { return {1, 2, 3, 4}; }
A a = {1, 2, 3, 4};
return a;
}
// 4. does not work
A mixed_named_unnamed(bool b) {
A a = {1, 2, 3, 4};
if (b) { return {4, 3, 2, 1}; }
return a;
}
In the latter case (4), the optimization cannot be applied when "A" is returned because the compiler cannot build "a" in the return slot, as it may need it for something else (depending on the boolean condition "b"). A simple rule of thumb is thus that: RVO should be applied if no other candidate for the return slot has been declared prior to the "return" statement.
Let's now have a look at the function to save an image as a PPM file:
void savePPM(const Image &img, const char *filename)
{
if (img.w == 0 || img.h == 0) { fprintf(stderr, "Can't save an empty image\n"); return; }
std::ofstream ofs;
try {
ofs.open(filename, std::ios::binary); //need to spec. binary mode for Windows users
if (ofs.fail()) throw("Can't open output file");
ofs << "P6\n" << img.w << " " << img.h << "\n255\n";
unsigned char r, g, b;
// loop over each pixel in the image, clamp and convert to byte format
for (int i = 0; i < img.w * img.h; ++i) {
r = static_cast<unsigned char="">(std::min(1.f, img.pixels[i].r) * 255);
g = static_cast<unsigned char="">(std::min(1.f, img.pixels[i].g) * 255);
b = static_cast<unsigned char="">(std::min(1.f, img.pixels[i].b) * 255);
ofs << r << g << b;
}
ofs.close();
}
catch (const char *err) {
fprintf(stderr, "%s\n", err);
ofs.close();
}
}
Here again the code is pretty basic. We don't save the image if one its dimension is zero. If the file can't be open then we throw an exception. We then write then header, the "P6" string, followed by the width, the height of the image and the number of grey values between black and white (255). Finally we loop over all the pixels of the frame. An unsigned char can only encode integer values in the interval [0,255], thus before multiplying the pixel color by 255 we first need to clamp its value to the interval [0,1]. Finally once converted to a unsigned char, the colors of the current pixels can be written out to the file.
Source Code
Full source code is available at the end of this lesson.
What's Next?
In the next lesson we will learn how to extend the functionalities of the image class and use operators for manipulating images in an easy way. We will demonstrate with an example, how we can use these simple features to simulate the blur which can sometimes see in the out-of-focus areas of real photographs.