An Introduction to Lighting in 3D Rendering
Reading time: 38 mins.This lesson is under development and is not yet complete. The material within this lesson is subject to change during its creation process (March 2024).
Preamble
Welcome to the lesson "Introduction to Lighting." As someone who has always held filmmaking dear, the topic of lighting in computer graphics is especially close to my heart. Unlike what I do with other lessons, I've included references in this lesson to videos and work that are not strictly related to coding and mathematics, but also to the use of lights in filmmaking. I strongly encourage readers to explore the work of people like director of photography Roger Deakins to find further inspiration (If you have other good references you'd like to share, please send them to me on Discord)..
In the lesson An Introduction to Shading, we briefly discussed lights and how to implement them in a rendering application. However, it might be challenging for readers to locate this information since it is embedded within the broader topic of shading. To ensure interested readers can find a lesson specifically devoted to implementing lighting in rendering, we've created this lesson.
What will you find here? As we reach the end of our section intended for readers new to CGI programming, this lesson continues in the same spirit as the previous ones. While we will provide a program that demonstrates how to implement different types of basic (and not so basic) light types, the produced image will remain rather simple, far from the beautifully crafted tech demos designed to impress. However, as you continue your journey, you will find that the next section dives into more detailed aspects of lighting. We will continue our study there, leading us to eventually produce images comparable to those from top-tier VFX and animation houses.
Until then, if you've already managed to digest the knowledge provided in this lesson, you should be well on your way toward mastery.
What Will We Learn in This Lesson?
In this lesson, we will introduce the various types of basic lights encountered in 3D rendering, mainly:
-
Distant light
-
Point and Spotlight
-
Rectangular and Spherical Area lights
In addition to our exploration of basic and advanced lighting types, this lesson will delve into the world of gobos, also known as projected textures, and other techniques (IES profiles and light color temperature) to mimic real-world lighting nuances.
We will learn how to implement and simulate each of these light types and understand when to use them. In other words, we will explore what each light type is useful for and what kinds of light effects we can simulate with them. Along the way, we will learn about the properties these lights possess, both from an engineering/physical standpoint and an aesthetic point of view. While technical, this lesson might be quite useful to CG artists interested in understanding why certain types of lights they use in their daily work have the properties and controls they do.
Although we will explore and implement these light types within a ray-tracing rendering framework, it's important to note that non-ray-tracing-based rendering frameworks, which are predominant in video game graphics (utilizing the rasterization algorithm), employ the same types of light. This lesson will cover how shadows can be simulated for these various light types by casting shadow rays from scene points towards the lights. In contrast, rasterization-based rendering engines utilize shadow maps, which present their own set of challenges. These include issues like bias and a fundamental lack of resolution, as shadow maps are constrained by a fixed resolution. Additionally, accurately simulating soft shadows with shadow maps, such as those cast by area lights, poses significant challenges.
Introduction
Before diving into the specific implementation of each light type, let's recap the fundamental role that light plays in generating images of 3D scenes. As we've mentioned in many lessons within this section, "without any light, you won't see anything." Light is fundamental to our ability to perceive the world. With this crucial point checked off our list, let's explore how light broadly works in computer simulations.
To simulate light-matter interaction with a computer, we need to consider 3 points:
-
Is the point in question, which we wish to know the brightness of, in shadow? That is, is the point visible from the light's position? Yes or no?
-
If the point is not in shadow, what is the contribution of the light to the point's illumination? This depends on the light type itself and the properties of the surface at the point of interest, notably its orientation.
Let's study each point individually:
Determining Whether the Point is in Shadow
In nature, light travels from the source, bounces off the surface of an object, and some of that reflected light eventually travels to our eyes, hitting the back surface of our eye, which is sensitive to light. We speak of forward tracing as we follow the natural path of light. However, during its journey, some photons emitted by the light source might be blocked by objects along their way. Objects immediately behind the trajectory of these blocked photons will not receive any light and will therefore appear in shadow.
In computer graphics, we tend to follow the path of photons backward, from the eye to the light source, for reasons already covered in the first lessons of this section. So, once a camera ray hits the surface of an object in the 3D scene, we want to know how much light is received by this point. To do so (assuming we have a simple light source for now), we then trace another ray called a shadow ray from the point in question to the light. If this ray intersects some geometry along its way to the light, then our point is in shadow. If not, it's illuminated by the light.
In ray-tracing, this type of ray is called a secondary ray. From a coding standpoint, these rays are simpler than camera rays because, while camera rays require gathering information about surface properties at the intersection point such as its normal and finding the intersection point closest to the camera, shadow rays do not. As soon as we have an intersection test that returns true, we can return because we know (and that's all we care about) that the point is in shadow. It doesn't matter whether this is the closest object from the point we are shading or not. Since all we care about is whether the light is blocked. So, essentially, these rays are generally cheaper to cast and don't require as much optimization and handling of corner cases as primary rays.
To sum up:
-
We cast a primary ray from the camera.
-
If this camera ray hits the surface of a 3D object in the scene, we cast a secondary ray or shadow ray from \(P\) to the light's position (for now).
-
If this shadow ray is blocked by some geometry, \(P\) is in shadow.
-
If this shadow ray is not blocked, we move to step 2: calculating the light's contribution to our point.
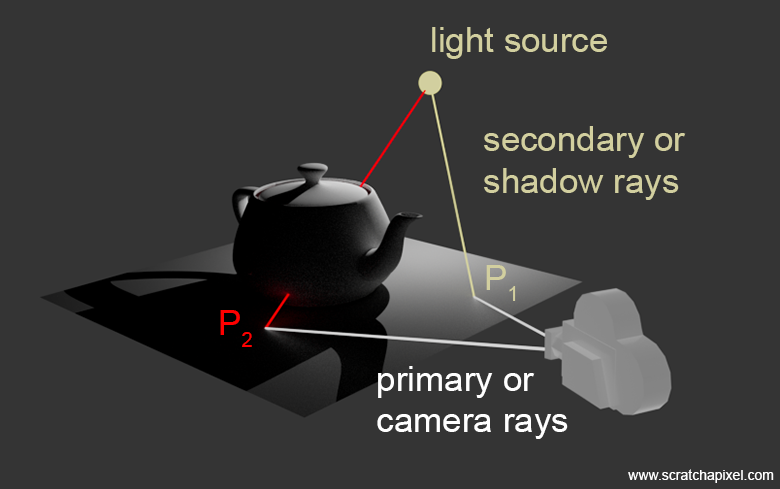
This principle is illustrated in the image above. We have two primary rays (in white) cast from the camera (eye) position into the scene. Each one intersects the plane in the scene at P1 and P2, respectively. While casting a shadow ray from P1 towards the light, we observe that the point is illuminated by the light source. As for P2, the shadow ray intersects the teapot at two places. The number of times the shadow ray intersects the geometry is irrelevant; our primary concern is whether the shadow ray intersects any geometry at all. As soon as we find an intersection (assuming the object is opaque - see below), we return. Therefore, P2 is in shadow, as clearly visible in the resulting render.
What happens if the object blocking the light is partially transparent? Surely, some light should be passing through it?! Yes, that's exactly how it works. When the shadow ray intersects an object that is detected to not be fully opaque, we must evaluate the object's opacity (generally by running the object's surface shader). Then, rather than returning 0 (in shadow) or 1 (not in shadow), what this ray needs to return is 1 multiplied by 1 minus the object's opacity. In this particular situation, we also need to keep testing for all remaining objects in the scene until we reach the light. If we find more objects along the way that are not completely opaque, then we repeat the process. If we find one that is totally opaque, then we simply set the ray's opacity to 0 and return. This is how we can simulate transparent shadows.
The principle is fairly simple and can be put in pseudocode as follows:
for (each pixel in the image) {
Hit hit;
Ray ray{orig, dir};
// Cast a primary ray into the scene
Intersect(ray, hit, prims);
// If the ray intersected an object, calculate the brightness/color
// of the object at this point (hit point).
pixel_color = 0;
if (hit) {
for (each light in the scene) {
Ray light_ray(hit_point, p_to_light_pos_norm);
bool in_shadow = Occluded(light_ray, prims);
if (in_shadow)
continue;
pixel_color += light_color * light_ray.dir.Dot(hit_normal);
}
}
}
This is really some rough pseudo-code, and some of the details it entails will be explained shortly. However, what's important to note for now is that, as is typical with ray tracing, we first loop over every pixel in the image and construct a primary ray for it. We've covered this process on numerous occasions (see, for example, Generating Camera Rays with Ray Tracing. From there, we check whether the ray intersects any geometry in the scene. If it does, we proceed to loop over each light in the scene and cast a shadow ray towards the current light. If the hit point is in the shadow of the light, then the light doesn't contribute to the point's color. Conversely, if the light is visible to the point, its contribution is added. Don't worry too much about the mathematics used for calculating the light's contribution; that part will be covered next. In the following chapter, where we will address the case of a point light, we will provide some actual code.
A noteworthy aspect of that code is that we use two different functions to calculate the ray-geometry intersection: one for the primary ray (Intersect) and one for the shadow ray (Occluded). This approach is extremely common in most renderers and is explained by the fact, as hinted above, that for shadow rays, we don't need to find the closest hit point to the ray's origin but only whether the ray intersected any (opaque) geometry at all. This process requires less work for shadow rays than for primary rays. Therefore, if we were using the same code for both (which would be entirely possible), we would likely miss an opportunity to optimize our program. To address this, we write a special function for the shadow rays that's optimized for the shadow case:
-
We omit any calculations related to the geometry at the intersection point.
-
We can return
truefrom the function, looping over all objects and every triangle making up each object in the scene, as soon as we find a positive hit.
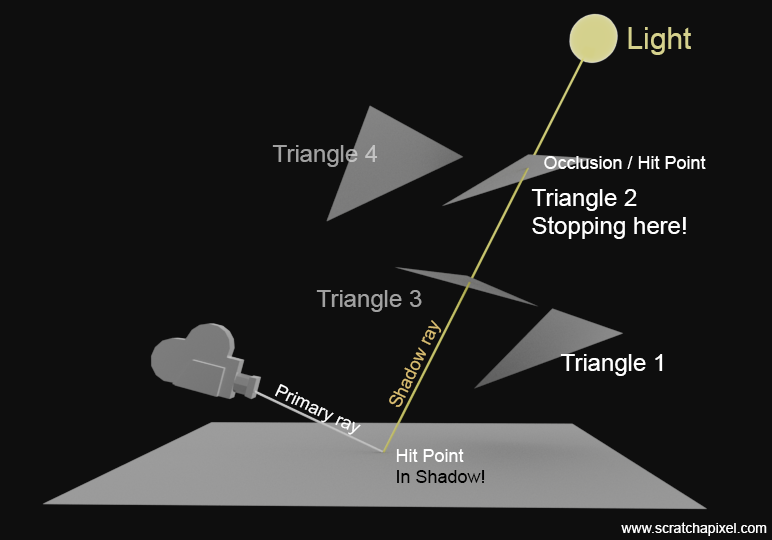
In case the principle isn't fully clear yet, we've illustrated it with a figure below. When a shadow ray is tested against four triangles in a scene, we don't know in advance the order in which the triangles will be tested due to the scene's construction. In this example, we first test Triangle 1 and find no intersection. Next, we test Triangle 2 and detect an intersection. Even though there is a Triangle 3 closer to the ray's origin than the intersection point with Triangle 2, we can immediately return from the function with the value true and ignore any further triangles. In this context, our primary concern is whether the shadow ray is blocked by any geometry, not identifying the blocking geometry. The mere presence of an occlusion is sufficient.
Calculate the Contribution of Light to Point P
Back to the topic of light. If the point is not in the shadow of the light, we need to calculate its contribution to the hit point's color. Using the term "color" here is not ideal, but keep in mind that in the real world, we are dealing with energy. Light consists of photons. The color of the lights depends on the photons' wavelength, and the more photons there are, the more energy is present. But more on that later. For this particular lesson, we will only consider surfaces that are purely diffuse, or in other words, matte. For more advanced shading models, check the series of lessons in Section 2. Diffuse surfaces have the nice property that the amount of light reflected by the surface is proportional to the cosine of the angle between the surface normal at the point of illumination and the light direction. We have mentioned this several times already, notably in the lesson Introduction to Shading. This is known as Lambert's Cosine Law.
We can write this law with the following equation:
$$I = I_0 \cos(\theta)$$Where \(\theta\) is \(N \cdot L\), with \(N\) being the normal at the surface, and \(L\) the direction from the point \(P\) to the light (see Figure 2).
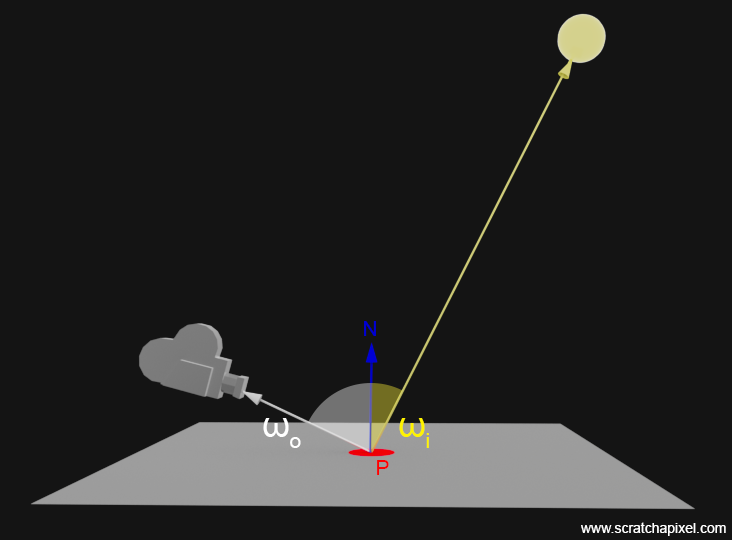
This notation can be a bit confusing because \(L\) is also used to denote radiance, a term we have looked at in the lesson on shading. Radiance denotes the quantity of light that passes through or is emitted from a particular area and falls within a given solid angle in a specified direction. Don't worry too much about these terms (solid angle, radiance, etc.) if you are encountering them for the first time. We will eventually get back to them later in this lesson. So, we will refer to the amount of light reflected at the point on the surface towards the eye by the letter \(L\) and denote \(wo\) and \(wi\) as the outgoing and incoming light directions, respectively. Whereas the outgoing light is the light that travels from the point to the eye, and the incoming light is the light striking our point from the light source, as shown in Figure 2.
$$L_o(\mathbf{w}_o) = L_e(\mathbf{w}_i) \cdot (\mathbf{n} \cdot \mathbf{w}_i) \cdot \text{V} \cdot \text{R}$$Here's what each term represents:
-
\(L_o(\mathbf{w}_o)\): The observed radiance in the outgoing direction \(\mathbf{w}_o\) (towards the viewer or camera).
-
\(L_e(\mathbf{w}_i)\): The radiance emitted by the light source in the incoming direction \(\mathbf{w}_i\) (from the point on the surface towards the light source).
-
\(\mathbf{n} \cdot \mathbf{w}_i\): The dot product between the surface normal \(\mathbf{n}\) and the incoming light direction \(\mathbf{w}_i\), accounting for the angle of incidence.
-
\(\text{V}\): A factor that accounts for shadows (\(V\) in this case stands for visibility).
-
\(\text{R}\): The reflectance properties of the material, determining how much of the incoming light is reflected in the outgoing direction. For perfectly diffuse surfaces, it is constant. More on that later.
This equation is important because it denotes a dependency on the quantity of energy received or reflected at point P and the incoming or outgoing direction. Interestingly, the amount of light reflected by a perfectly diffuse surface is independent of the viewing direction \(\mathbf{w}_o\). It is constant, which is why we start with a diffuse surface for convenience. That constant is \(1/\pi\). If you're curious about the reason, we invite you to read the lesson A Creative Dive into BRDF, Linearity, and Exposure. Don't worry if this equation feels abstract; we will delve into a concrete implementation in the next chapter.
Note that we've included a term \(\text{V}\) in our equation to account for shadows or occlusions, as discussed earlier. In this lesson, this will simply be either 0 or 1, indicating whether a point is in or out of shadow (visible or invisible to the light).
Note also that arrows in Figure 2 might be a bit misleading. Light is emitted by the light source, and some of it will shine upon the surface at point \(P\). So, the fact that the yellow arrow is pointing from \(P\) to the light is just to indicate the direction of the "un-normalized" \(\omega_i\) vector in this figure's case. Both vectors \(\omega_o\) and \(\omega_i\) are indeed typically pointing away from \(P\).
Equipped with this information, all we need to do is apply this formula in our code to simulate the contribution of light to our hit point \(P\). If the light is visible from point \(P\)—which we check in step 1—we then calculate the cosine of the angle between the surface normal and the light direction \(\omega_i\), multiply this by the light intensity (which is color, a Vec3, if you prefer) and multiply the whole thing by the material reflectance, which, as suggested for diffuse surfaces, is \(1/\pi\). Really simple.
Note that there can be more than one light in the scene. We will discuss this in more detail in the last chapter of this lesson, but the contribution of lights to the illumination of \(P\) is linear. So, all you'll need to do is loop over all the lights in the scene and accumulate their contribution using the same logic we just introduced above (calculate the cosine of the angle, multiply by light color, etc.).
Now, as you can imagine, there are different types of lights, and they all have their specificities. Let's present them briefly before looking into how to implement each one specifically, which will be the topic of the next chapters.
Light Types: Delta vs. Area Lights
Lights can be divided into two broad categories: delta lights and area lights. In the real world, all lights are physical objects with mass, size, and shape. However, as we will see when we get to the area light types, simulating lights with physical size and shape in computer graphics is not a straightforward problem. In the early years of CG development, particularly when computers had only a handful of megabytes of memory and limited CPU power, researchers preferred to work with "ideal" representations of physical lights. They aimed to simulate light types most commonly found in nature: sphere lights, projectors, and the sun. It turns out that the models they developed for these represent lights as ideal lights, which peculiarly have no size at all. A point light is just a singular point in space assumed to radiate light in all directions. And because a point is a pure mathematical construct without an equivalent in the physical world, we designate them by the name of delta light. This is because the delta function in mathematics is used by mathematicians to define a shape that doesn't exist in the physical world. The delta function is indeed 0 everywhere but at zero, and the integral of the function is equal to one. So are our lights; so there are called delta lights.
In some textbooks, you might see these types of lights defined mathematically as:
$$Li(\omega) = L\delta(\omega - \omega_{\text{light}})$$where \(\omega\) represents any direction above the hemisphere centered around the shaded point, and \(\omega_{\text{light}}\) effectively represents the light direction. Here, \(\delta\) is the Greek letter delta, used to represent the delta function. This definition indicates that the function returns 1 only when \(\omega\) and \(\omega_{\text{light}}\) are identical. In all other cases, it will return 0.
What you'll want to remember is that these lights are called delta lights because they share the delta function's characteristic of being considered point-like or having no discernible size in rendering calculations. This simplification was made to manage certain computational aspects of rendering more efficiently, notably those involved in the computation of shadows and reflections, as we will explore in the following chapters.
While somewhat historical, delta lights are still very much in use in production today, though area lights are preferred whenever possible. Now, for reasons beyond the scope of this introduction, they have caused considerable headaches for CG artists. The problem with delta lights is that they have no size. Precisely, this means we can't get the lights to cast shadows or reflect on objects like real lights do. Think about it: How do you represent the reflection of a light if it's a singular point in space? Even Da Vinci couldn't figure this one out. So yes, they were better than nothing and played a critical role for decades in our ability to produce CGI that impressed the crowd, but at the cost of sacrificing physical correctness.
Area lights, as their name suggests, have a physical size and thus do not suffer from this issue. However, their adoption was slow initially because simulating them requires a considerably greater amount of computing power. However, these days, thanks to the billions of transistors contained within GPUs and CPUs, using area lights no longer means dealing with stalled computers. And that means we can get accurate shadows and reflection and create images that are said to be physically correct.
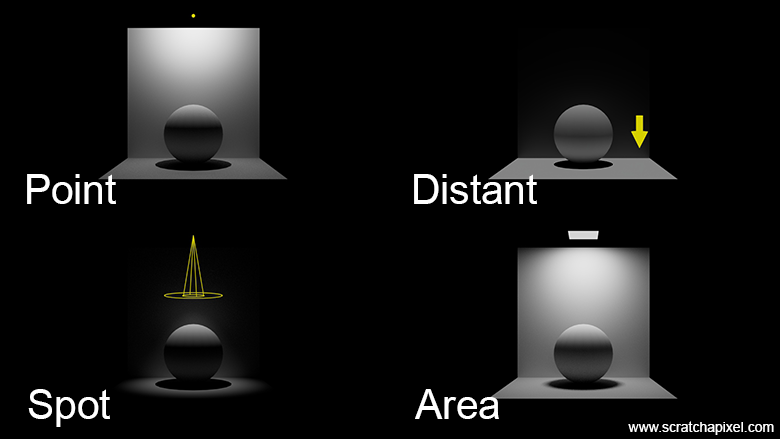
With this distinction between delta and area lights established, we can now proceed to study the specifics of each light type and explore how to implement them. In this lesson, we will study the following four different types of lights:
-
Point: Mimics the behavior of a perfectly spherical light.
-
Distant (also known as directional light): Mimics the behavior of the sun.
-
Spotlight: Acts like a projector, featuring a cone and a falloff.
-
Area Light (quad and sphere): Typically rectangular or sphere-shaped.
The first three lights belong to the category of delta lights, while area lights fall into the area light category, of course. The following image shows the scene rendered by each type of light.
For completeness, let's mention three additional light types we won't be studying in this lesson:
-
Environment Lights (including Skydome Lights): These are special lights that simulate the sky or the environment around us. If you've heard of the use of HDRI maps for lighting, those are what these images are used for. It's the contribution of the environment to the illumination of your scene. A lesson devoted to the implementation of environment lights can be found in Section 2 (HDRI image provided by Hdri-Haven).
-
Geometry Lights: The area lights typically used in CG have "simple" shapes such as rectangles, tubes, or spheres. This is convenient because these shapes can be represented mathematically, which simplifies the computation of shadows and reflections. Geo lights are polygonal meshes (most commonly) that emit light. Because they can have arbitrary shapes and topology, they are much harder to deal with than quad or spherical lights.
-
Volumes: Volumes too can emit light, such as candle flames or explosions.

There are two more terms we want to introduce before moving on because you might encounter them in various tools and API documentation.
-
Punctual lights: This term is used to distinguish spotlights and point lights from distant lights. The difference, as we will see when implementing each type, is that point and spotlights have a position in space. In contrast, a distant light, which mimics the sun's behavior, does not (we only consider the light direction).
-
Photometric lights: These lights are generally punctual lights (point or spot) that use what we call IES or EULUMDAT light profiles. These profiles, measured from real-world lights, provide the amount of energy emitted by the lights based on direction. This technique, which we will discuss again briefly later in this lesson, is excellent for adding complexity to the point and spotlight sources, which remain essentially very simple in their appearance and lack the ability to simulate how real light looks and the effect they have on illuminating the surrounding scene.
Light Linearity
Read this section carefully.
One very important property of light, as discussed in the introduction to shading, is that each light's contribution to a scene is linear. This means if you have two lights in a scene, and you render two images of the same scene illuminated successively by each of these lights, then sum up the two images, the result will be exactly the same as rendering the scene with both lights on simultaneously. The contribution of each light can simply be summed up in a loop. Therefore, as long as you know how to calculate the contribution of a single light—a concept we will explore in the following chapters—rendering a scene containing more than one light simply involves looping over each of these lights, applying the same logic to each, and adding their contributions to the point being shaded.
std::vector<Light> lights;
Vec3<float> L = 0;
for (const auto& light : lights) { // Corrected 'light' to 'lights'
L += light_dir.Dot(hit_normal) * Vis(hit_point, light_pos) * material_reflectance;
}
// Save the "color" of the point into the image
buff[(y * image_width + x)] = L;
Check the last chapter of the lesson to see the working code that implements this idea.
Radiance vs Irradiance
Now we've introduced the concept of observed radiance \(L_o\) (where the \(o\) can also stand for outgoing) so while you have been exposed to the concept of radfiance already you might also come across the term of irradiance. Remember that radiance (see the lessons An Introduction to Shading and The Mathematics of Shading) is radiometry quantity that measures the the desnity oif radiant flux (power) per unit of surface area per une of soliud angle. Irradiance only measure the density of radiant flux per unit of surface area. So to sum up:
-
Irradiance: measures the amount of light incoming to a certain point from all directions.
-
Radiance: measures the amoiunt opf light incoming to a point from asignle direction.
First of all, irradiance at a certain point on a surface is the density of radiant flux (power) per unit of surface area, while radiance at a certain point on a surface in a specific direction is the density of radiant flux per unit of surface area and per unit of solid angle. In simple terms, irradiance is the amount of light arriving at a certain point from potentially all directions, whereas radiance is the amount of light arriving at a point from a single direction.

Now, the amount of light incoming to a point \(x\) through a small cone \(d\omega_i\) around direction \(\omega_i\), with solid angle size denoted \(d\sigma(\omega_i)\), is called radiance \(L_i(\omega_i)\). This incoming small beam of light generates some irradiance on the surface at \(x\). That is, the surface is now able to emit light in exchange for light impinging on its surface (light is reflected back into its environment). This "partial" irradiance is denoted \(dE(\omega_i)\). We use "partial" to suggest the fact that it is only the irradiance (light reflected in all directions by the surface) being reflected as a contribution to the light incoming from a small, narrow light direction. Some of the incident light is being absorbed, while some is being scattered (reflected) in all directions. The out-scattered contribution of \(L_i(\omega_i)\), \(dE(\omega_i)\), to radiance outgoing in direction \(\omega_o\) is denoted as \(dL_o(\omega_o)\). Experimentally, you can verify that the amount of outgoing radiance \(dL_o(\omega_o)\) is linearly proportional to the incoming irradiance \(dE(\omega_i)\), and this ratio is what the BRDF (Bidirectional Reflectance Distribution Function) captures:
\[f_r(\omega_i \rightarrow \omega_o) = \frac{dL_o(\omega_o)}{dE(\omega_i)}\]
Where \(f_r\) is a common way of denoting what we know as a BRDF (Bidirectional Reflectance Distribution Function) in rendering equations. Note that \(f_r\) essentially refers to what we mentioned earlier as the material reflectance. (You can find a quick introduction to BRDF in the lesson A Creative Dive into BRDF, Linearity, and Exposure).
This relationship is one of the key concepts in rendering, alongside the rendering equation itself, which is explored in a dedicated lesson in the advanced section.
Light Intensity, Light Color, and Dynamic Range Images
It's important to distinguish between light intensity and light color. In most 3D software, these two properties are presented to the user as separate parameters, but this is mainly for convenience or artistic control. In reality, they are intertwined. Light, per se, is a mixture of photons vibrating at different wavelengths. The mix of wavelengths that each photon contributes to defines the light color. As mentioned in the previous lesson of this section, light can be described as a continuous spectrum of wavelengths, and a similar spectrum can vary in amplitude, depending on how many light particles are contained within a beam of light. The more photons, the more energy.
As you know, in computer graphics, we tend to represent color as a combination of three main colors: red, green, and blue. We don't use the spectrum because 1) it's computationally more expensive (imagine dealing with 16 samples instead of 3), 2) we often don't have spectrum data readily available for a wide range of common materials, and 3) adjusting a color by tweaking a spectrum is much harder than moving a point on a color wheel, which combines three primary colors (in the additive system). Considering light can be much greater in intensity than the range provided to represent color (limited to 256 values per channel for most consumer screens), we tend to separate colors from light intensity (defined as "intensity" in most 3D applications, generally just a float).
To sum up:
-
Light colors are generally defined as a triplet of values, either floats (within the range 0-1) or as a single byte (allowing representation of 256 values).
-
Light intensity is represented as a float.
To calculate the final light contribution, we multiply the light color by its intensity. In the real world, this combination would be embedded in the light spectrum, with the distribution of wavelengths making up the light defining its color and the amplitude of the spectrum representing its energy.
Remember that unless we use high-dynamic range image formats (HDR, EXR, TIFF, etc.) or screens (though screens are much more limited in the range they can display, due to the human vision system being itself limited in the range of light it can adapt to—a limitation images don't have since they can store values within arbitrarily large ranges), we will have to store the final pixel values making up our image within a single-byte range value per channel (RGB). So even if we use floats to represent color, we will need to convert float-based colors into unsigned bytes at the end of the rendering process, prior to storing values to a file (assuming again here that we use a low-dynamic range format such as PNG, JPG, PPM, etc.).
Also, to clear something that might be confusing, it's not because our initial light color multiplied by its intensity goes way above 1 that the amount of light reflected by the surface is necessarily greater than 1, though this is also entirely possible. For reasons we will explain in the next chapter, light intensity decreases with the square of the distance between the light source and the point upon which the light shines. Therefore, even if the amount of light at the origin of emission is very high, by the time it reaches a surface, it might have decreased significantly. Also, remember we need to multiply that number by the cosine of the angle between the surface normal and the light direction, as well as by the material reflectance, both values being lower than 1. So, all in all, what's reflected by the surface can be lower than 1 (assuming floating point values are used here) even though light arriving upon the surface initially could have been greater than 1.
The purpose of the following code snippet is to demonstrate how the concepts we've discussed are implemented in practice. In this code, we opt to define colors using floats. This is almost universally the case in today's rendering systems because floating points are fast, and using floats instead of a single byte per channel offers more precision. So, even though we might convert the values from float back to 1-byte at the end, the process is less destructive than if we had conducted all our computations before storing the final values in the image using a 1-byte/channel approach. Note that the following code is not accurate (it's pseudo-code, not precise in that sense) because we don't take into consideration the light falloff we just mentioned. We will address that in the next chapter. The goal of this snippet is more about showing you how we typically perform all our computations for lights and colors using floating point values and how we convert them back to 1-byte/channel, which is expected when storing pixel values into a low dynamic range image format. Note that this process carefully requires that we clamp values within the range [0:255].
std::unique_ptr<uint8_t[]> image_buffer = std::make_unique<uint8_t[]>(width * height * 3);
uint8_t* cur_pixel = image_buffer.get();
Vec3<float> light_color(0.9, 0.95, 0.8);
float light_intensity = 10;
for (each pixel in the image) {
// Wrong here because we don't take into consideration light intensity square falloff
// but check the next chapter for 'better' code.
Vec3<float> L = std::max(0.f, light_direction.Dot(hit_normal)) * light_color * light_intensity * 1.f / M_PI;
// Convert back to range [0:255]
Vec3<uint8_t> pixel_color(
static_cast<uint8_t>(std::min(255.f, L.x * 255)),
static_cast<uint8_t>(std::min(255.f, L.y * 255)),
static_cast<uint8_t>(std::min(255.f, L.z * 255)));
std::memcpy(cur_pixel, &pixel_color.x, 3);
cur_pixel += 3;
}
// Store image buffer to a file
...
Light Temperature
In the real world, light is emitted by objects that are being heated. Incandescent lights, for instance, emit light as a result of electricity passing through a thin filament, which, when brought to a very high temperature, emits light. Fluorescent lights work on a similar principle except that electricity is used in this case to ionize a gas contained within the bulb, which as a result emits light. As you know, the surface of the sun is very hot. Interestingly, there's a relationship between the temperature at which an object is heated and the "color" of the light it emits. At lower temperatures, light is within the orange tones. As the temperature increases, it becomes "cooler" and moves towards blue tones. This effect and how to calculate the color as a function of the object's temperature have been explained in detail in the lesson on Blackbody Radiation, where you can find an in-depth explanation of what the phenomenon is and how to calculate the color based on the object's temperature.
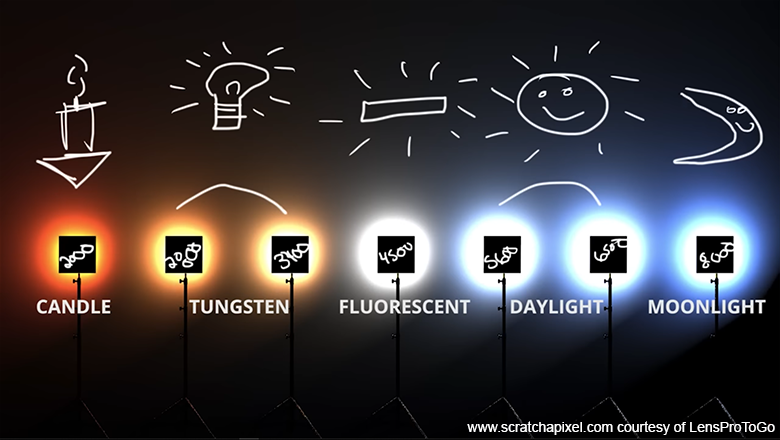
This is known as the light color temperature. It is a well-known effect by directors of photography, who have to consider this property of light very carefully, as it has a big impact on the overall image color tone (as shown in Figure 4. Source: LensProToGo). Indeed, artificial lights brought to low temperatures emit an orange type of color, which can give images an overall orange color, which we associate with warmer/cosy types of mood. Lights that are within much higher temperatures emit blue light, which can be perceived from an artistic standpoint as creating cold-like types of mood. So one has to know and consider this property of light when used for either architectural simulations or for creating specific moods in films.
Now in practice, CG artists rarely specify the color of a light using the temperature parameter. Most advanced rendering software, such as those found today in 3D animation tools and video game engines (Arnold, Pixar's PRMan, Unreal Engine, etc.), allow you to specify the temperature instead of specifying an RGB color. Internally, the software will calculate the resulting RGB color based on the provided temperature. In practice, at least in our production experience, CG artists generally prefer to specify the light color using the standard RGB color panel.
This leads us to the fact that, besides the range of color temperatures a physical light can emit, any other light color is generally produced in films, at least, by adding some sort of colored coating around the light source. An effect that you can more easily reproduce by adjusting the RGB color setting.
How Does Our CG Lighting Relate to Real-World Physical Lights?
Before we delve into the next chapter, which will explore the implementation of a point light, you may wonder how to simulate a specific light, such as the one on your desk at home, using computer graphics. In other words, how can you translate real-world physical units—like power, light temperature, and shape—into a virtual representation that accurately mimics the effects on synthetic objects, effectively recreating the scene?
We have previously covered various elements, such as light temperature, surface albedo (the ratio of reflected to incoming light), the physical shape of the light source, and the concept of brightness in relation to energy. While we've thoroughly explored the first three factors, understanding that the shape can be fully modeled to create what's known as a "geo light," we are now left to address the intricacies of brightness and energy. This aspect presents challenges primarily due to two significant reasons:
-
The human vision system is non-linear, meaning our perception of brightness is somewhat subjective.
-
The energy consumed by a light does not directly correlate with the amount of light it produces. For instance, a LED light may consume less power than an old-fashioned light bulb but can be just as bright.
Additionally, as discussed in the lesson A Creative Dive into BRDF, Linearity, and Exposure, rendering navigates the complex interplay between two distinct yet intertwined models: photometry and radiometry. Radiometry, the cornerstone of computer graphics, quantifies electromagnetic radiation, including light. In contrast, photometry focuses on measuring light as perceived by the human eye, using units like candela, lumens, and lux, commonly found on lighting equipment in hardware stores. The challenge arises when attempting to convert these perceptually based photometric units into the linear, measurable units of radiometry—radiance, irradiance, and intensity—given the inherent discrepancy between the subjective human experience of brightness and the objective, linear metrics of radiometry.
The intricacies of rendering mirror those found in photography, particularly concerning the sensitivity of the sensor or the camera's exposure time to light. Longer exposure times invariably lead to brighter images, while the lens aperture and ISO settings further modulate the brightness of objects or lights within the image. These factors add layers of complexity to the rendering process, intertwining with the fundamental differences between photometric and radiometric measurements to present a multifaceted challenge in accurately simulating real-world lighting conditions in computer-generated imagery.
As you can see, accurately simulating a LED light from a hardware store in CG, using the photometric data provided on the box, is not straightforward. However, if we know the albedo of objects in the scene, we are left with two specific aspects of light behavior:
-
Its brightness (the amount of energy it radiates)
-
The directionality of its energy emission. Lights do not emit energy equally in all directions. Most lights have a unique profile describing how much energy is emitted as a function of direction. These profiles, known as IES profiles, are crucial for professionals like architects to accurately render buildings or streets illuminated by specific light types, since they can simulate using these IES/ELUMDAT profiles. Knowing an object's albedo and the light's IES profiles allows us to adjust the light intensity until we achieve a render that looks plausibly similar to real-life observations. Knowing these details ensures we can approximate the needed adjustments to energy levels accurately, even if converting photometric to radiometric units is complex.
This approach does not mean we should skip the step of attempting to convert photometric measurements to radiometric units. It merely acknowledges the complexity of this conversion and sets it aside for a focused discussion in a dedicated lesson. You can find a lesson devoted to using IES/EULUMDAT profiles in the Computer Graphics Gems section.

It's worth noting that in computer graphics (CG), lights are typically assumed to emit light equally in all directions. This is the case for general-purpose spot and point light sources, but it results in fairly bland and unrealistic profiles. However, the advantage, as mentioned earlier, is their simplicity to estimate. Creating lights that produce the same results as those achievable through IES profiles is entirely feasible and often practiced by car manufacturing companies designing car headlights. They need to preview the output of these designs before construction, which requires modeling the glass, mirrors, and every component part of the light, undergoing physically accurate light simulation that takes reflection and refraction into account. Such simulations can take hours for just a single light, making them unrealistic for production rendering. This is why using IES profile "tricks" can add complexity to scenes lit by a simple point or spot light while maintaining the benefits of such simplistic models for fast rendering.
The assertion that simple light types are used in CG animation/VFX is no longer entirely true. Since the 2010s, the use of area lights in production has become quite common, thanks to increased computing power now sufficient for rendering scenes with area lights in acceptable times. Though, while area lights might be preferred, replicating complex light profiles, even with area lights, is challenging. Therefore, IES profiles offer the best approach here. Almost every rendering system and video game engines (Arnold/Maya, Redshift, Unreal Engine, Godot Engine, Pixar's PRMan, etc.) supports photometric lights using IES/EULUMDAT profiles for this specific reason. Therefore, if you're using one of these applications, it's highly probable that you'll have the capability to configure photometric lights.

As an illustration, the adjacent image shows a screenshot of an Arnold Photometric light in Maya. You can see the parameter for specifying the IES profiles that you wish to use for the light. It also includes an option to use color temperature for the light (and calculating this value on the fly) rather than setting up the color as a triplet of RGB values.
Summing Up
What have we learned so far:
-
We learned that integrating lights into our rendering process is a two-step process:
-
Occlusion: Is the light visible from the shaded point?
-
Illumination itself: What is the contribution of that light to the shaded point? We learned that this depends on the light direction, the light distance (a concept we are yet to study in detail), the light color, intensity, the surface normal, and the material reflectance (not mentioning the visibility or occlusion factor we spoke about earlier).
-
-
We learned that lights' contributions can be linearly summed up. This simplifies the code, requiring only that we loop over all lights in the scene and add their contribution.
-
We learned about the different types of lights and the categories they fall into: delta (spot, point, distant) and area light, and we made a distinction between punctual light (spot, point) and distant light (sun) in the delta light category.
-
We learned about IES/EULUMDAT profiles.
-
And we learned about light color temperature. While not often used, some 3D software gives you access to it as an alternative to setting up the light color as a standard triplet of RGB values.
If there's one thing you need to remember from this chapter, it's the definition we provided for the BRDF: there is a relationship between the amount of light incoming at a point \(x\) from a given direction \(dL(\omega_i)\) and the light that is being reflected by a surface as a result of this impinging light, denoted \(dL(\omega_o)\), and that there is a function called BRDF that mathematically describes the ratio between the two. Note that for diffuse surfaces, the BRDF of a diffuse (matte) surface is \(\frac{1}{\pi}\) (as explained in the lesson A Creative Dive into BRDF, Linearity, and Exposure).
That's a lot. Well done. It's time we write some code and see how these concepts are represented in practice.
References
These references lean more towards the artistic side, but for readers passionate about the use of light in filmmaking, these videos are inspiring. Roger Deakins is one of the greatest directors of photography currently working.
White Balance & Kelvin Color temperature explained.
Roger Deakins and the Art of Practical Lighting.
1917 Explained by Cinematographer Roger Deakins.
